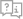钢闸门是给排水工程、水利、水电工程中常用的拦水、止水设备,由门框、闸板、密封圈及可调式锲型压块等部件组成。钢闸门久用磨损后,其密封面可通过锲型压块的调整来保证正常工作。钢制闸门以优质钢板为基材,采用橡胶止水...

主要由闸框、闸板、吊座及紧闭斜铁等零部件组成。为克服以往钢门易锈蚀的缺点,闸框、闸板全采用铸铁组成,其中闸框又由上横梁、下横梁、左直梁、右直梁组成。为了制造、运输、安装方便,闸板一般根据其大...

钢坝闸门,也称景观闸门,属于闸门技术领域,是新一代钢制闸门产品。主要适用于河面相对较宽且水位落差小的工况条件使用,景观效果较好...

清污机是将拦污和清污结合为一体的固定式连续清污设备。主要栅体、清污耙、驱动传动系统,辅助栅四部分组成;其主要应用于泵站、水电站、倒虹吸等水工建筑物的进水口处,它以拦污栅拦截水流中所携带的污物...

闸门启闭机型号及规格繁多,可以分为:QLP型、QLS型、QLC型、QPQ型、QPK型、QPG型、QPT型、QHQ型等不同型号以及0.3T-50T、3T-100T、5T-125T等不同规格...


 黄色综合 拍门——主要安装在排水管道的尾端,用于防止外水倒灌。 ★材质分为不锈钢、铸铁、型钢、等多种材料。 ★安装在江河边排水管出口的一种单向阀,当江河潮位高于出水管···...
黄色综合 拍门——主要安装在排水管道的尾端,用于防止外水倒灌。 ★材质分为不锈钢、铸铁、型钢、等多种材料。 ★安装在江河边排水管出口的一种单向阀,当江河潮位高于出水管···...  A级高清视频欧美日韩 ...
A级高清视频欧美日韩 ...  国产亚洲色婷婷久久99精品 ...
国产亚洲色婷婷久久99精品 ...  成年免费视频 ...
成年免费视频 ...  A级毛片视频 铸铁闸门安装相关信息:1、 安装前,要首先检查竖框与横框之间、闸板与闸板之间的连接螺丝,是否在运输装卸中引起松动,它们的接茬是否错牙,要调整成一个平面,检查闸板···...
A级毛片视频 铸铁闸门安装相关信息:1、 安装前,要首先检查竖框与横框之间、闸板与闸板之间的连接螺丝,是否在运输装卸中引起松动,它们的接茬是否错牙,要调整成一个平面,检查闸板···...  看免费黄色视频 铸铁闸门安装相关信息:1、 安装前,要首先检查竖框与横框之间、闸板与闸板之间的连接螺丝,是否在运输装卸中引起松动,它们的接茬是否错牙,要调整成一个平面,检查闸板···...
看免费黄色视频 铸铁闸门安装相关信息:1、 安装前,要首先检查竖框与横框之间、闸板与闸板之间的连接螺丝,是否在运输装卸中引起松动,它们的接茬是否错牙,要调整成一个平面,检查闸板···... 
检测报告及资质齐全,生产的产品规格齐全,品质倍可靠;执行水利行业生产 制造, 出厂前执行严格的二次入库验收标准,确保质量稳定;研发工程师8名,更有10年以上经验的技工。

便于实行自动化和远动化等优点,容量可达8000 kN 或更大,行程达12m以上.按工作特点分单作用和···...
2024-04-07
便于实行自动化和远动化等优点,容量可达8000 kN 或更大,行程达12m以上.按工作特点分单作用和双 作用两种。前者在提升闸门时,压力油作用在油缸的活 塞杆腔···...
2024-04-07
闸门用来封闭和开放水道或管道的控制设施。利用闸门可以拦蓄水流,控制水位,调节流量,引水发电或灌溉,运放船只、木排,排泄泥沙、冰块及飘浮物等。它是水工建筑物上的重···...
2024-04-07
(1)拆下锈死的滚轮,将轴和轴瓦清洗除锈后涂上润滑脂。没有注润滑油设施的,应在轴上加钻油孔,轴瓦上开油槽,用油杯或黄油枪加注油脂润滑。(2)轴与轴承的摩擦部分应···...
2024-04-07
 亚精区区一区区二在线
亚精区区一区区二在线 河北强宁水利机械有限公司是一家专业设计、制造、批量生产及指导安装水工机械的综合性企业。我公司具有完善的现代化管理模式、专业的生产设备,同时我们还建立健全了产品质量检测及维护服务体系,设备齐全,检测手段完善,具有专业的生产技术,产品深受省内外用户的好评及依赖。 我公司集科研、设计、开发、生产、施工为一体,专业生产钢制闸门、铸铁闸门、不锈钢闸门,QL型、QLC型、QLP型螺杆启闭机,QPQ、QPK、QPH、QPT型卷扬启闭机启闭机,玻璃钢拍门、钢拍门、不锈钢拍门、拦污栅、回···... 了解更多
 91视频网址
91视频网址  手机二维码 微信二维码
手机二维码 微信二维码
15227696661 1123034094@qq.com 衡水市冀州区西王镇东罗口

 看免费黄色视频
看免费黄色视频 波多野结衣一二三区
波多野结衣一二三区 岛国一区二区三区
岛国一区二区三区 成人91污污污在线观看
成人91污污污在线观看 日日夜夜7799天天
日日夜夜7799天天 欧美日韩啪啪
欧美日韩啪啪 激情综合站
激情综合站 国产日韩综合
国产日韩综合 黄色毛片视频
黄色毛片视频 欧美福利导航
欧美福利导航 日韩a级视频
日韩a级视频













![[nav:name]](http://haruhi.club/temp/0100/static/picture/1601191497879506.jpg) 营业执照
营业执照